Delphi - сбориник статей
Программная реализация трансляции формулы
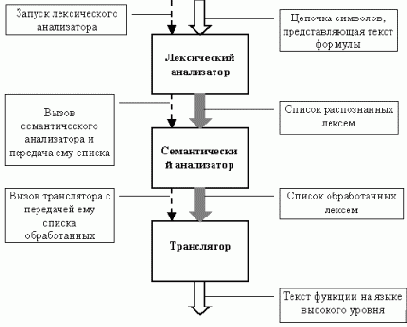
Обработка формулы состоит из следующих этапов:
Лексический анализ: входящий поток символов разбивается на лексемы. Выделение очередной лексемы производится путем посимвольного анализа теста формулы, разбор идет до тех пор, пока есть символы на входе. Если обнаружена неизвестная лексема, то разбор прекращается и выводится сообщение об ошибке с указанием места в тексте формулы, где была найдена эта лексема. После успешного завершения этого этапа будет сформирован список из "допустимых" лексем. Этот список можно использовать в побочных практических целях, например, выполнить "красивое" форматирование текста формулы.
Семантический анализ: список лексем проверяется, на то, что они образуют в совокупности допустимую формулу. Если обнаруживается ошибка, то выдается сообщение об ошибке с указанием места ошибки и ее описанием. Семантический анализатор построен по принципу конечного рекурсивного автомата, который каждая следующая лексема переводит из одного допустимого состояния в другое или выбрасывает исключительную ситуацию (переводит автомат в недопустимое состояние). Для каждого типа лексем есть набор правил (из выше описанной грамматики) определяющих как их анализировать в зависимости от текущего состояния автомата. После этого этапа получается список "обработанных" лексем. Этот список может отличаться от списка после первого этапа, так как семантический анализатор может добавлять, удалять и изменять лексемы в процессе анализа, например, будут добавлены лексемы умножения, которые согласно определению языка описания формул могут опускаться при записи формул.
Трансляция: опираясь на проверенный список лексем, формируется текст функции на языке высокого уровня которая, будучи скомпилированной, в составе некоторой программы будет вычислять заданную формулу.
Описанный подход можно представить в виде следующей схемы: